Using the fw ingest project Command
Introduction
In version (14.4.0), Flywheel introduced a new way to copy an entire Flywheel project to a new location by using the CLI. The Ingest project command streamlines multi-site collaboration as well simplifies workflows where data is curated on a pre-production Flywheel site before being moved to a production site.
The Ingest project CLI command can be used to copy data:
- From one Flywheel site to a different Flywheel site that is on the same version
- From one group to a different group within the same Flywheel site
Warning
Unsupported upload method for site, group, or project de-id profiles
Use one of these supported methods if you use site, group, or project de-id profiles.
Problems and Resolutions
N/A
Instruction Steps
- Sign in to the source project. You must have create container and upload data permissions on the source project.
The source project is the Flywheel site or project that contains the data you want to copy.
- For the site with the source project, obtain your User API Key. You will need this later on. Learn more about creating User API Keys from the Profile page.

- If you are moving the project to a new site, sign in to the destination project. You must have download permissions on the destination project.
- In the destination project, note the group and project label, or create new ones.
- Open Terminal or Windows Command Prompt, and sign in to the destination with the CLI. Learn more about how to download and install the CLI.
To see where you are signed in, enter fw status in Terminal. If you are not signed in to the destination, obtain your User API Key for the site with the destination project. Learn more about creating User API Keys from the Profile page.
- Enter the following command in Terminal:
- -- group and --project: Add the destination group id and project label. For example
--group betagroup --project "beta project" - SRC: The routing string from the source group and project. For example:
fw://alphagroup/alphaProject - FW_WALKER_API_KEY: The API Key from the source Flywheel site. For example:
flywheel.io:yiLr8PHLtpe33IdYJ5 - If you have ingest cluster deployed on your environment, add the
--clusterflag to utilize the cluster's compute power. Learn more about using a cluster. Learn more about using a cluster.
Learn more about all of the optional flags in the reference section below.
For example:
fw ingest project --group betagroup --project "beta Project" fw://alphagroup/alphaProject flywheel.io:yiLr8PHLtpe33IdYJ5
Note
If you do not specify the group and project by adding the --group and --project flags, Flywheel will look for a group and project that matches the Source.
- Flywheel begins scanning the source project and displays the results.
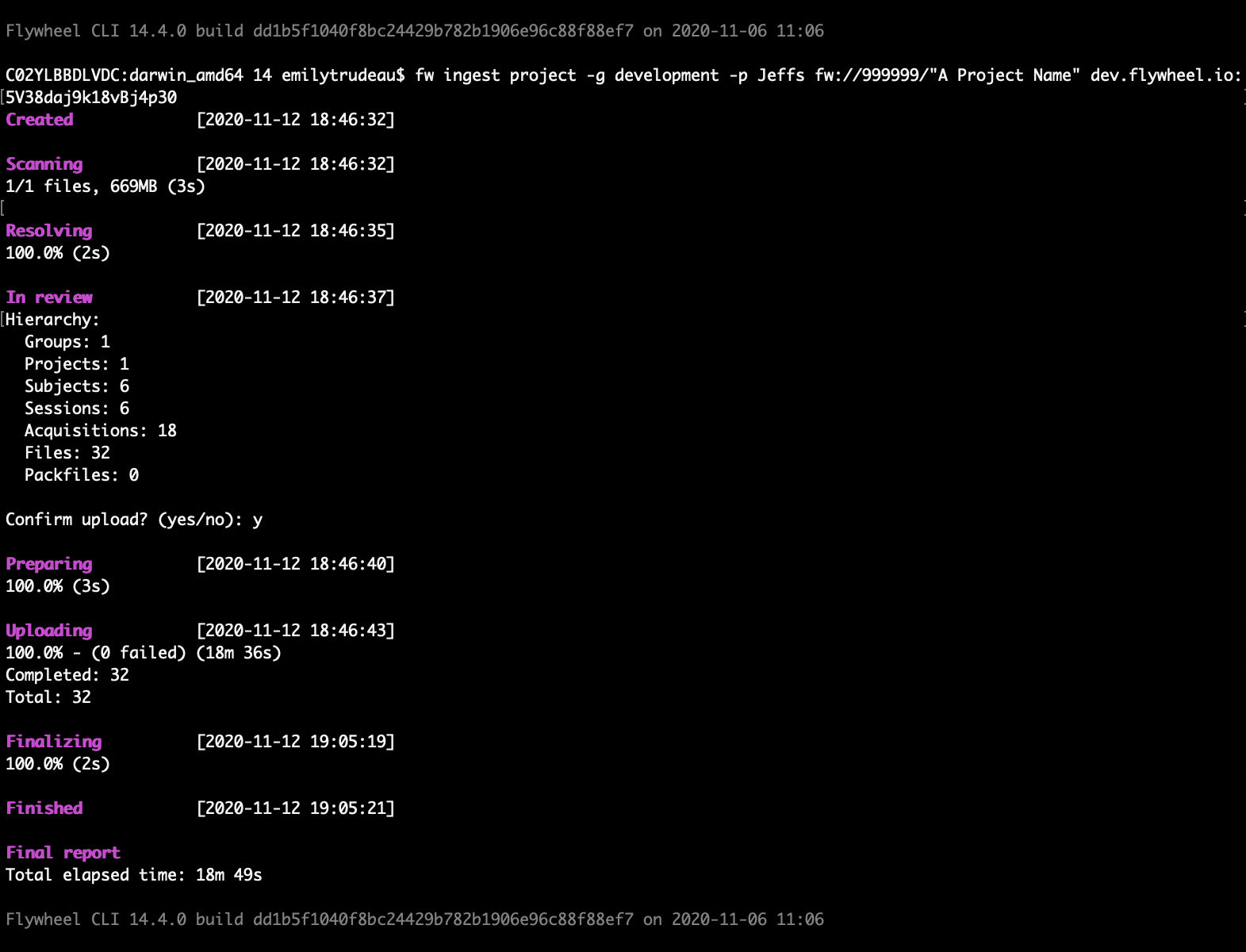 8. Review the summary, and enter
8. Review the summary, and enter yes.
Note
Flywheel ingest project command will copy the Source data and metadata, but not:
- Job history/provenance
- Analyses
- Change log history
- Project permissions
- Gear Rules
- Session templates
-
Data Views
-
Once the scan is complete, go to the destination project to view.
Existing containers are not modified in destination project, and any existing files are not copied over.
Considerations
- Empty containers in the Source will not be copied to destination
- When copying projects between sites, both sites must be on the same version.
- The file origins in the destination show that the data was uploaded by a user
- Only one project can be migrated per CLI command
- The source project is copied to destination. The source project is not modified or deleted and remains on the Source site.
Command reference
Ingest Project Command Options
| Argument | Help Text |
| Positional arguments | |
| SRC | The path to the folder to import (e.g.: fw://group-name/project-name/) |
| FW_WALKER_API_KEY | Your API key for the Source Flywheel site (e.g.: flywheel.io:yiLr8PHLtpe33IdYJ5) |
| Optional arguments | |
| -h, --help | show this help message and exit |
| --compression-level COMPRESSION_LEVEL | The compression level to use for packfiles -1 by default. 0 for store. A higher compression level number means more compression. |
| --copy-duplicates | Upload duplicates found using --detect-duplicates to a sidecar project instead of skipping them (default: False) |
| --de-identify | De-identify DICOM files (default: False) |
| --deid-profile NAME | Use the De-identify profile by name |
| --detect-duplicates | Identify duplicate data conflicts within source data and duplicates between source data and data in Flywheel. Duplicates are skipped and noted in audit log (default: False) In the audit log the error categories are: - DD01: multiple files have the same destination path - DD02: file name already exists in destination container - DD03: a single item contains multiple StudyInstanceUIDs - DD04: a single session contains multiple StudyInstanceUIDs - DD05: multiple sessions have the same StudyInstanceUID - DD06: StudyInstanceUID already exists in a different session - DD07: a single acquisition contains multiple SeriesInstanceUIDs - DD08: multiple acquisitions have the same SeriesInstanceUID - DD09: a single item contains multiple SeriesInstanceUIDs - DD10: SeriesInstanceUID already exists in a different acquisition - DD11: SOPInstanceUID occurs multiple times (image uids should be unique) |
| --detect-duplicates-project DETECT_DUPLICATES_PROJECT [DETECT_DUPLICATES_PROJECT ...] | Specify one or multiple project paths to use for detecting duplicates |
| --enable-project-files | Enable file uploads to project container (default: False) |
| --encodings ENCODINGS [ENCODINGS ...] | Set character encoding aliases. E.g. win_1251=cp1251 |
| --exclude PATTERN [PATTERN ...] | Patterns of filenames to exclude |
| --exclude-dirs PATTERN [PATTERN ...] | Patterns of directories to exclude |
| -g ID, --group ID | The id of the destination group (default comes from SRC) |
| --ignore-unknown-tags | Ignore unknown dicom tags when parsing dicom files (default: False) |
| --include PATTERN [PATTERN ...] | Patterns of filenames to include |
| --include-dirs PATTERN [PATTERN ...] | Patterns of directories to include |
| --load-subjects PATH | Load subjects from the specified file |
| --no-audit-log | Skip uploading audit log to the target projects (default: False) |
| -p LABEL, --project LABEL | The label of the destination project (default comes from SRC) |
| --require-project | Proceed with the ingest process only if the resolved group and project exists (default: False) |
| --skip-existing | Skip import of existing files (default: False) |
| --symlink | Follow symbolic links that resolve to directories (default: False) |
| General | |
| -y, --yes | Assume the answer is yes to all prompts (default: False) |
| --ca-certs CA_CERTS | The file to use for SSL Certificate Validation |
| -C PATH, --config-file PATH | Specify configuration options via config file |
| -d, --debug | Turn on debug logging (default: False) |
| --no-config | Do NOT load the default configuration file (default: False) |
| -q, --quiet | Squelch log messages to the console (default: False) |
| --timezone TIMEZONE | Set the effective local timezone for imports |
| -v, --verbose | Get more detailed output (default: False) |
| Reporter These config options are only available when using cluster mode with the --follow argument or when using a local worker | |
| --save-audit-logs PATH | Save audit log to the specified path on the current machine |
| --save-deid-logs PATH | Save deid log to the specified path on the current machine |
| --save-subjects PATH | Save subjects to the specified file |
| Cluster These config options apply when using a cluster to ingest data. | |
| --cluster CLUSTER URL | Recruits resources from the cluster on which your Flywheel site is installed (V3). Use when uploading a large amount of data. Note: Ingest clusters are not deployed by default contact your Flywheel admin to see if this option is available in your environment. |
| Your cluster URL is the URL you use to sign in followed by /ingest. For example: https://university.flywheel.io/ingest | |
| -f, --follow | Follow the progress of the ingest (default: False) |
| Worker These config options are only available when using local worker (--cluster is not defined) | |
| --jobs JOBS | The number of concurrent jobs to run (e.g. scan jobs) |
| --max-tempfile MAX_TEMPFILE | The max in-memory tempfile size, in MB, or 0 to always use disk |
| --sleep-time SECONDS | Number of seconds to wait before trying to get a task |